首先,客户需要爬取的页面是: http://www.huobiao.cn/search?word=&block=1 底下各个标的详情数据。
如果没有登录的话,招标详情一些关键信息会被隐藏,像这样:
而登录后这些信息都会展示出来。
经过分析,本次爬虫需要向三个页面请求数据,第一个是登录页面,第二个是请求每一页中的数据,第三个根据返回的数据找到每个公告的详情网址,向这个网址请求详细的数据。这么说有点抽象,直接来看每一步做了什么。
第一步,登录
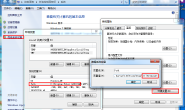
打开开发者工具,选择network一栏,按照如图所示的顺序操作。
首先点击登录,会弹出一个登录框,但是在开发者工具并没有看到网址发生变化,猜测只是一个js操作,起了一个线程,网址没有发生变化。但是这不影响我们操作,我们不输入任何登录信息,直接点击“立即登录”,一个网址赫然在列:
可以看到请求的网址是: http://www.huobiao.cn/do_login, 请求携带三个数据以供服务器校验,由此构造requests请求:
login_session = requests.Session()
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36’,
‘Referer’: ‘http://www.huobiao.cn/search?word=&block=1’,
}
def login():
data = {
‘phone’: ‘xxxxxxxx’,
‘password’: ‘xxxxxxx’,
‘check’: ‘on’,
}
# 按照服务端的需要构造请求,并获得session,记录在login_session
response = login_session.post(‘http://www.huobiao.cn/do_login’, data=data, verify=False, headers=headers)
print(response.content)
打印一下这个response看一下返回的内容,返回一个json格式的数据:
b'{“code”:”1″,”msg”:”\u767b\u5f55\u6210\u529f”,”ret_data”:[],”timestamp”:1537496282}’
其中的msg内容看起来像是一个unicode字符串,去站长工具网站(http://tool.chinaz.com/Tools/Unicode.aspx)转化一下看看是什么内容:
b'{“code”:”1″,”msg”:”\登\录\成\功”,”ret_data”:[],”timestamp”:1537496282}’
OK,长舒一口气。
第二步:请求列表页信息
当我们在列表上点击搜索的时候,会出现一个非常可疑的请求:
经过分析,这个正是请求列表详情的url,请求的网址是:http://www.huobiao.cn/do_search,我们来看一下请求的数据和返回的数据:
请求的json数据是这样的:
也即是:
{“type”:”0″,”time”:”1537496995″,”province”:”全国”,”start”:””,”end”:””,”category”:””,”item”:”0″,”page”:1,”word”:””,”project_type”:””,”tap”:1}
这里也就是网页上的搜索条件,其中page和time值得注意,page表明了当前列表的页数,time是一个10位的数字,是一个unix时间戳。我们按照这个格式建造一个请求。
def search_list():
s_l = []
for i in range(5):
time.sleep(3)
search = {
“type”: “0”,
“time”: str(int(time.time())),
“province”: “全国”,
“start”: “”,
“end”: “”,
“category”: “”,
“item”: “0”,
“page”: i+1,
“word”: “”,
“project_type”: “”,
“tap”: 1,
}
s_l.append(search)
return s_l
好了,我们带着这些数据,向http://www.huobiao.cn/do_search 请求数据吧。得到的是一个json格式的二进制json字符串数据,解析这个json数据之后:
好了,我们看到了很多有用的数据,title,address,当然,对我们最重要的是href了,当然这个href需要加上:http://www.huobiao.cn 拼接一下才能正常访问。这个href就是我们最终需要的招标详情页的url了。还剩最后一步:爬取招标详情页!
第三步:爬取招标详情页
在第二步获得的url,在这一步将被直接通过get请求获得信息,之后通过BeautifulSoup解析需要的数据,将需要的数据存入Excel表格中。
完整代码如下:
from bs4 import BeautifulSoup
import requests
import json
import time
from xlutils.copy import copy
from xlrd import open_workbook
login_session = requests.Session()
# 按照网页的请求构造请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36',
'Referer': 'http://www.huobiao.cn/search?word=&block=1',
}
def login():
data = {
'phone': '18668115440',
'password': 'wasd122816',
'check': 'on',
}
# 按照服务端的需要构造请求,并获得session,记录在login_session
login_session.post('http://www.huobiao.cn/do_login', data=data, verify=False, headers=headers)
def search_list(page):
search = {
"type": "0",
"time": str(int(time.time())),
"province": "全国",
"start": "",
"end": "",
"category": "",
"item": "0",
"page": page+1,
"word": "",
"project_type": "",
"tap": 1,
}
return search
def home():
for page in range(5):
# 登录后,客户端将会向这个网址请求数据
response = login_session.post('http://www.huobiao.cn/do_search', data=search_list(page), headers=headers, allow_redirects=False)
# 返回的是一个json的二进制数据,先将其转成utf-8编码格式
answer = str(response.content, encoding="utf-8")
# 再将json格式转成dict格式,方便处理
diction = json.loads(s=answer)
for company in diction['ret_data']['list']:
try:
# 获得每个公告的主页url,这个url不是完整的url,需要拼接
company_url = company['href']
company_url = 'http://www.huobiao.cn'+company_url
# 用登录时获得的session继续请求每个公告的主页,这样就可以保持登录状态
company_detail = login_session.get(company_url)
soup = BeautifulSoup(company_detail.content, 'html.parser')
row = {}
row['project_name'] = soup.find('div', class_='dm-main').find('h6', class_='title').get_text().strip()
row['project_company'] = soup.find('div', class_='dm-main').find('div', class_='cw-top').find('span', class_='address').get_text().strip()
row['pubtime'] = soup.find('div', class_='dm-main').find('div', class_='cw-top').find('span', class_='pubtime').get_text().strip()
row['board_content'] = soup.find('div', class_='dm-content').find('div', class_='cw-reftext').find('a')['href']
table = soup.find('table')
t_r0 = table.findAll('tr')[0]
# 由于公告内容的格式不一样,两种格式需要分别处理
row['G'] = t_r0.findAll('td')[0].get_text().strip('\t')
# 有正规的表格的是以2开头的时间
if row['G'][0] == '2':
row['main_content'] = ''
for p in soup.find('div', class_='dm-content').find('div', class_='cw-maincontent').findAll('p'):
row['main_content'] += p.get_text()
row['H'] = t_r0.findAll('td')[1].get_text().strip()
t_r1 = table.findAll('tr')[1]
row['I'] = t_r1.findAll('td')[0].get_text().strip()
row['J'] = t_r1.findAll('td')[1].get_text().strip()
t_r2 = table.findAll('tr')[2]
row['K'] = t_r2.findAll('td')[0].get_text()
row['L'] = t_r2.findAll('td')[1].get_text()
else:
# 没有正规表格就把全部数字都抓取下来
row['main_content'] = soup.find('div', class_='dm-content').find('div', class_='cw-maincontent').get_text()
row['G'] = 'none'
row['H'] = 'none'
row['I'] = 'none'
row['J'] = 'none'
row['K'] = 'none'
row['L'] = 'none'
except Exception:
continue
else:
rexcel = open_workbook("deal.xls") # 用wlrd提供的方法读取一个excel文件
global_row = rexcel.sheets()[0].nrows # 用wlrd提供的方法获得现在已有的行数
excel = copy(rexcel) # 用xlutils提供的copy方法将xlrd的对象转化为xlwt的对象
table = excel.get_sheet(0) # 用xlwt对象的方法获得要操作的sheet
table.write(global_row, 0, row['project_name'])
table.write(global_row, 1, row['project_company'])
table.write(global_row, 2, row['pubtime'])
table.write(global_row, 3, row['board_content'])
table.write(global_row, 4, row['main_content'])
table.write(global_row, 5, row['G'])
table.write(global_row, 6, row['H'])
table.write(global_row, 7, row['I'])
table.write(global_row, 8, row['J'])
table.write(global_row, 9, row['K'])
table.write(global_row, 10, row['L'])
global_row += 1
excel.save('deal.xls')
print(company_url)
print(row)
if __name__ == '__main__':
login() # 处理登录
home() # 获得每个公告的主页并分别处理它们 大功告成!
转载请注明:夜阑小雨 » python爬虫requests登录并跳转抓数据